Sの場合、1行に2つ以上のデータ点(フィールド)があっても勿論かまわないし、
データが文字データを含んでいてもよい。データ間は空白で
区切られていると仮定されるが、その他の
文字(Tab)などを区切りとして用いる事もできる。文字データがある時に
空白も文字として扱う時はTabで区切る必要がある。またひとつのファイルに
複数の曲線のデータを入れる時は、空行で区切るのではなく、
NA NA ...
が必要なデータ数(フィールド数)だけ入った行で区切る必要がある。
例えば、
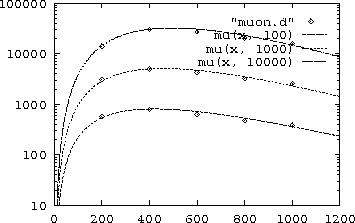
200 570 depth vs number of muons. 100 TeV 400 785 600 621 800 474 1000 383 NA NA 200 3.07e3 1000 TeV 400 4.91e3 600 4.24e3 800 3.21e3 1000 2.53e3 NA NA 200 1.4e4 10000 TeV 400 2.99e4 600 2.69e4 800 2.01e4 1000 1.56e4あるファイルfielexの空行を全てそうした行に置き換え, fileyにセーブするには、 Terminalで
awk '{if(NF>0) print; else print "NA NA ..."}' filex > filey
とすればよい。
逆にNAの行を空行に変えるには、
awk '{if($1 == "NA") print "" ;else print}' filey > filez
のようにすればよい。
こうしたファイルをSで使うには、Sの中で、
xxx <- scan("filey", list(x=0, y=0), flush=T)
等として、scan関数で読み込む。xxxは各自で決める適当な名前である。
listのところはデータの雛形を示すもので、上記では、1行から2つの数値
データを読む(x=0等の0は数値の代表として示されている。0の変わりにどんな
数値でもかまわない)。1行に3つ以上のデータがあってもflush=Tの指定で
無視される。各行の終りに注釈などがある場合に便利に使える。
x=0, y=0等に現れる名前(x, y...)は各自が適当に選べる名前で、
必ずしも1文字である必要はない。例えば、温度のデータと、
濃度のデータが組みになって入っている場合は、
list(temp=0, con=0)等にすれば分かりやすいであろう。
こうしてxxxに取り込んだデータは通常
x <- xxx$x
y <- xxx$y
の様にして、分解して使う。
温度と濃度の例では、
temp <- xxx$temp
con <- xxx$con
等とすれば分かりやすい。
ただし、単順にプロットするだけなら分解せず、
plot(xxx, type="l")でよい。
後は、関数プロットの時と同じである。